万物皆有鄙视链。
据说在有些互联网公司面试的时候,面试官都喜欢问候选人一个问题,“你平时活跃在哪个技术社区”?如果答案是GitHub或者StackOverflow,那就是一个加分项;如果答案是CSDN,那么很可能成为减分项,甚至是不被录用的判断依据之一。
CSDN是中国最大的程序员社区。在其2023年发布的新闻稿中,它声称自己“拥有超过4500万注册用户”和“6000多万篇文章”。
让CSDN在一些面试官眼中成为减分项的关键,正是来自这6000多万篇文章——它们构成了中文互联网上极为庞大的内容农场之一,更关键的是,它带了一个很不好的头,稀土掘金、简书等内容平台也开始主动或被动效仿。
电影院里,一旦前排的人站起来了,后面的观众就不得不跟着站起来,才能看得见屏幕。
CSDN就是那个第一个站起来的。
第一代内容农场:自己做内容,外面找流量
内容农场并非新生事物,而是伴随着搜索引擎的发展而出现的“寄生物”。
早在2009年,美国一家名叫Demand Media的内容农场公司老板就对《连线》杂志(Wired)放出豪言,声称要“每个月产出100万篇文章,相当于每年制造四个维基百科”。第二年,也就是2010年,雅虎斥资9000万美元(约合人民币6亿)收购了另一家同类公司 Associated Content。
要知道,同年美团刚从红杉拿到了1200万美元的A轮融资,而当时如日中天的百度2009年的营收也不足45亿元人民币。内容农场受“资本家”的青睐程度由此可见一斑。
原因非常简单,内容农场同时满足了“开源”和“节流”的需求。一方面,从搜索引擎带来的滚滚流量,为这些网站产生了不少的广告收入,这也是互联网公司最主要的收入来源之一;另一方面,据说当时内容农场为每篇文章开出的稿费仅为3.5美元,远低于付给人工撰写稿件的20美元左右的稿费标准。
与这些美国公司不同的是,CSDN成为内容农场或许并非有意为之,而是历史发展之巧合。
海量内容只是内容农场成功的必要条件之一,基本上花钱和堆人头就能办到,但是另一个必要条件——获取流量的门槛就要高许多。在那个年代,人们搜索互联网上的内容主要依赖的还是搜索引擎。通过技术手段,让搜索引擎抓取到页面,并且将它尽量排到搜索结果列表的前面,这个技术叫做“搜索引擎优化”,简称为SEO。
作为一个技术社区,CSDN的SEO技术显然是足够强的。至于内容的来源,它并没有像美国人那样发稿费雇人来写。当时,很多国内的技术牛人喜欢在CSDN博客上发布文章来分享经验和技术,这些文章增加了CSDN的权重;与此同时,越来越多的后来者和新手也开通了CSDN博客,但是他们更习惯将它作为学习笔记来使用,于是产生了大量的内容类似甚至完全相同的文章。
当文章数量达到某个级别并突破阈值后,搜索引擎终于被攻占了。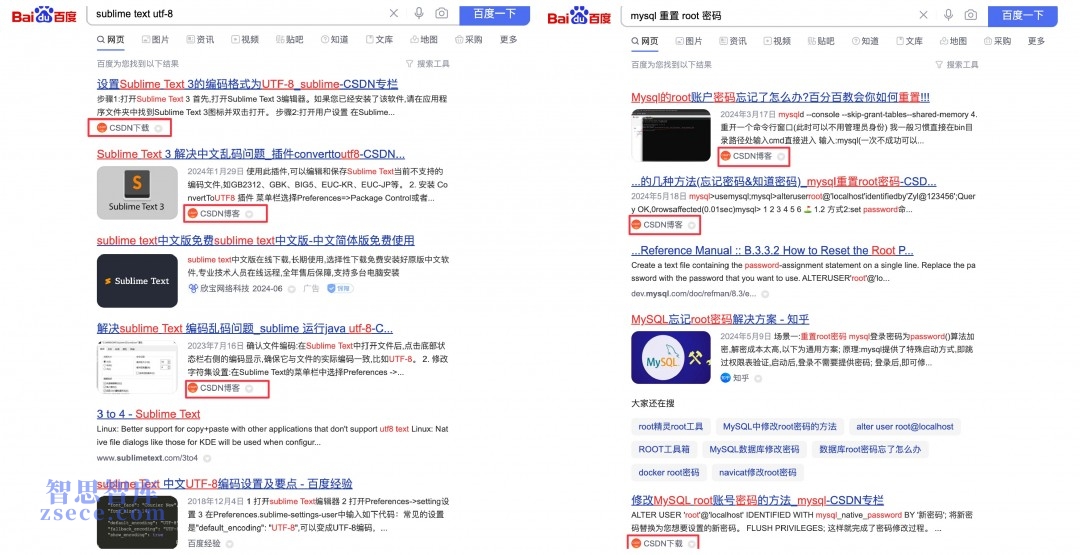

十几年来,搜索引擎对内容农场的态度基本上是持否定的,毕竟类似上图这样的搜索结果非常影响用户体验。不过从实际情况来看,自从2010年百度最大的竞争对手退出中国市场之后,稳坐国内搜索引擎头把交椅的百度,并没有从根本上——也就是从技术和规则上去解决这个问题,相反的,一大批类似的网站如雨后春笋般出现。
现在,你在百度搜索技术问题的话,除了CSDN之外,首屏出现的大概率还会有博客园、稀土掘金、简书……以及耳熟能详的那几家云计算厂商的“技术社区”,他们将大量过期的、重复的技术文档复制来复制去,一边浪费着自己的服务器和带宽,一边浪费着用户的时间。
面对这个局面,大部分程序员还是选择了接受,否则CSDN也不会有4500万用户了。
第二代内容农场:搬别人的内容,养自己的流量
当智能手机开始普及,手机流量开始管饱,人们使用互联网的方式变了。买东西会在电商APP中搜索,看视频会在视频APP中搜索,看小说会在阅读APP中搜索……浏览器和搜索引擎不再成为必经之路。

那些新入行的程序员们,也不再是看着CSDN们的博客学习,B站成了它们的新欢。虽然依然有很多程序员在把博客当笔记,但是从搜索到的内容来看,明显是比之前少了。
在这种流量池各自为政的情况之下,新的内容农场出现了。不过这一次,他们不再自己生产内容,而是通过技术手段,将别人创作的内容进行二次加工来产生大量内容,然后再以此获得更多的平台推荐。到了短视频全面普及之后,这种迹象更加明显。
与前一个时代不同的是,这种形式的内容农场,不但更容易得到平台的支持,用户对之也更容易接受,因为省去了自己搜索的麻烦。所以,除了部分原创作者的吐槽之外,倒是鲜见有用户对此有怨言。
AIGC时代:自己编内容,自己有流量
OpenAI一声炮响,拉着全球网民进入了AIGC新时代。
前面说过,形成内容农场有两个必要条件:一是内容,二是流量。到了AIGC时代,一分钟内可以生成数篇内容类似但又不完全相同的文章,内容的数量和质量都远超之前。这些AI生成的内容迅速出现在微信公众号、小红书、知乎之类的内容平台,不过此时仍然处于上一个时代的范畴,AI只负责生产内容。
直到今年五月,有用户在使用字节跳动旗下对话式AI产品“豆包”时发现,其答案的参考来源竟然来自豆包自身生成的内容,至此,AI时代的内容农场初具雏形。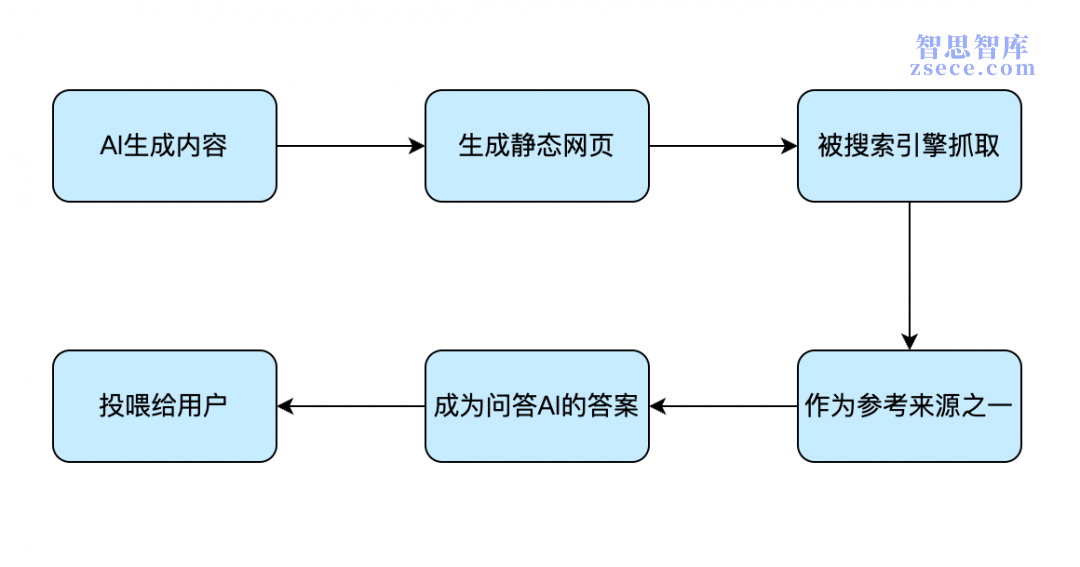

也就是说,如果你日常将对话式AI当作与互联网交互的入口的话,那么看到的答案完全有可能也是来自AI自身,而这些AI生成的答案中,本身又可能存在不准确甚至荒谬之处,比如之前广为流传的“小帅与小美”(很多电影解说短视频给男女主角取的名字)就曾被AI当作参考答案。
虽然此次“事故”被迅速修复,但是几乎所有对话式AI都具备这个能力,而且此次被用户发现,是因为“豆包”使用自有的域名(doubao.com)来生成静态页面,如果使用的是一个看起来和字节跳动没有任何关系的域名的话,那么很可能永远都不会被用户发现。
立法层面,目前的相关的法律法规主要针对的是“有害内容”,对于这种低质但无害的内容并没有明确约束,所以似乎只能靠厂商的自我约束了。
厂商的确在行动,不过这些行动更多的是在“交互入口”处建立壁垒。比如百度的搜索引擎,将自己的AI“文心一言”生成的答案排在了最上面,这属于“用魔法打败魔法”;知乎的AI“知乎直答”也是给自己的数据更高权重。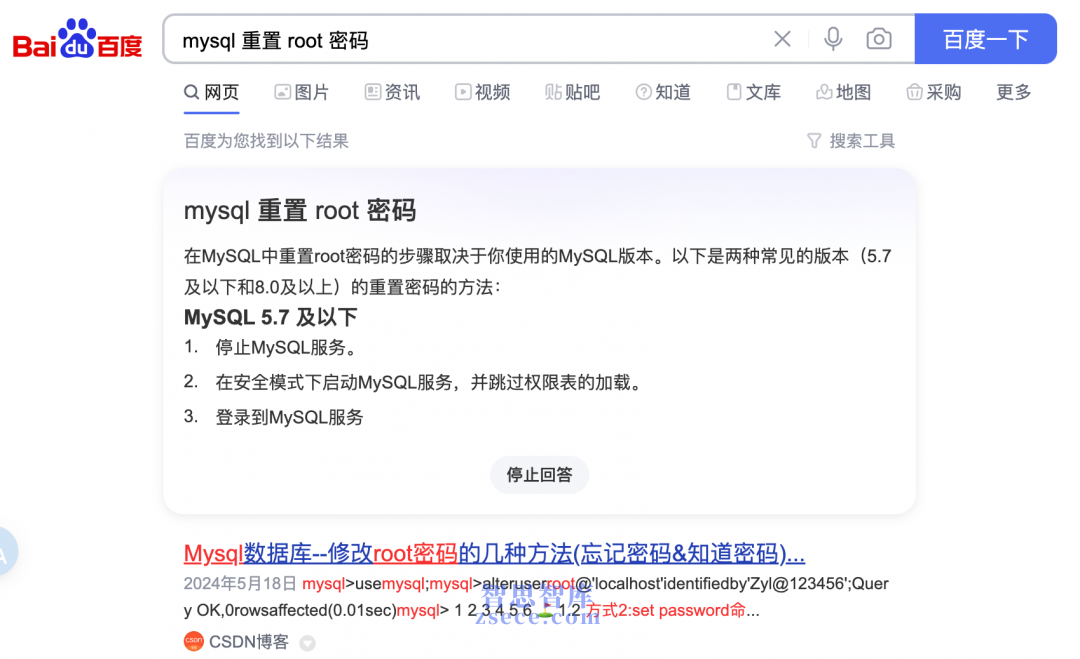

唯一值得庆幸的是,当下对话式AI还没有成为人们与互联网交互的主流,人们还有时间来完善这个体系,避免AI内容农场的大规模出现。
我们可以怎么办?
第一代内容农场时代,程序员们尚且可以通过各种技术手段——比如使用浏览器插件uBlacklist在搜索结果中排除指定的网站——来规避内容农场出现在搜索引擎的结果中,或者干脆使用工具来阻断对这些网站的访问,但是普通人无能为力。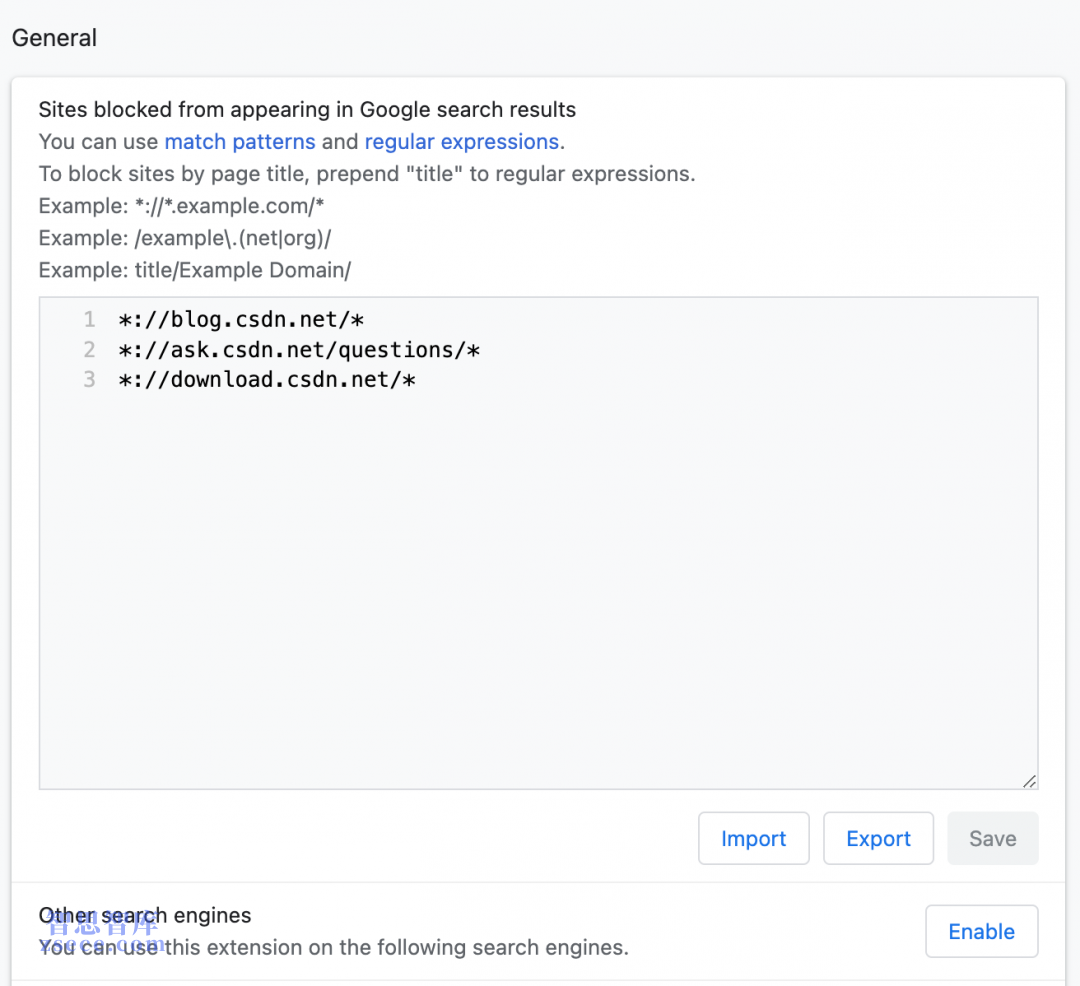

第二代内容农场时代,只有少部分人会选择去屏蔽那些搬运者,大部分人都选择了接受投喂。
面对即将到来的AI内容农场,人们可以怎么办?你又会怎么办?